
Last year (2022) I’ve started to learn Go and how you can achieve that easily? well … start building something with it…
The Challenge
In my projects I’ve encountered an interesting use case where a team needed to test the transformation of data from one source database to another target database.
You guess it, it is a case of ETL (extract, transform and load) where a sequential process extracts data from source systems, transforms the information into a consistent data type, then loads the data into a single repository.
As you see, the first challenge is to design this program so testers can define their own queries easily (without touching the codebase of the tool).
So what functionalities should this have, if I will be the tester that will write or run the queries daily?
Functionalities:
- the tool should accept easily source and target database(s)
- the queries will be executed on source and target databases and results are compared one by one
- differences are highlighted and displayed in a … HTML report
- testers can run any query they want (or all of them)
- testers can run queries on differed source and targets
Those are ok for now, but what quality attributes should I focus on?
- Usability: the tool should be easily configured. Testers should write new queries easily, define new source & target databases on the go..
- Portability: the tool should run on differed operating systems (on Mac, on Linux on Windows..
- Maintainability: the tool should be easily modified, improved or adapted to new requirements.
- Performance: the tool should execute and compute the queries faster. The tester should not spend time waiting for results.
The Solution
Behold select-star -> a CLI(command line interface) tool written in GO that will process queries defined in YAML files
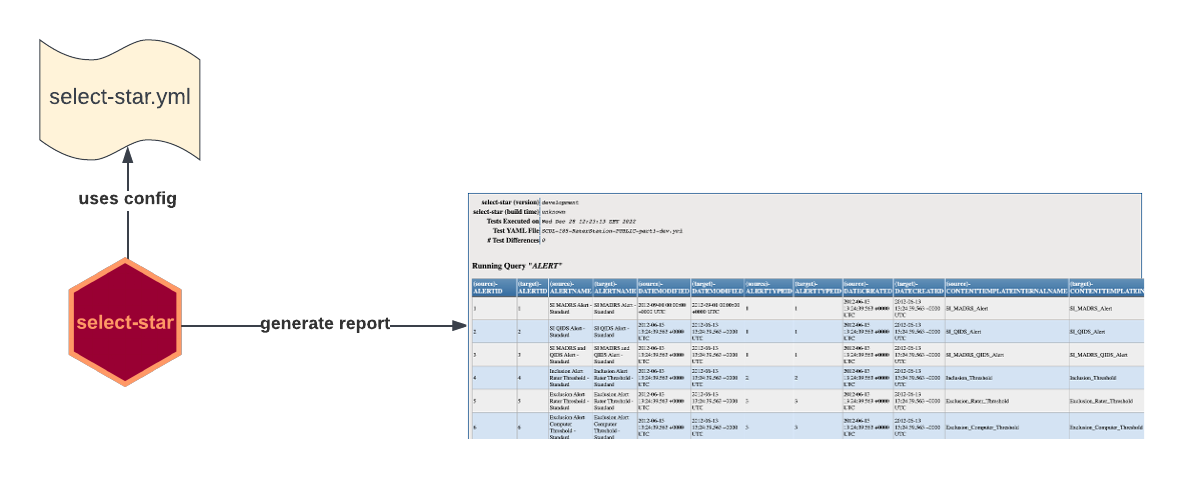
The tool will look by default for a select-star.yml configuration file (in current or your user’s home folder) where you can define source and target DBs along with SQL queries that will be executed.
The results returned by the queries will be compared row by row and the differences will be saved by default in a timestamped HTML report.
Everything is controlled by YAML configuration file(s) where you defined the source DBs or target DBs, queries, variables used.
You can also define mappings or corelation between a source object and a target object (e.g. column A in source maybe is renamed A_up in target).
These mappings will be used when we run the queries.
Architecture
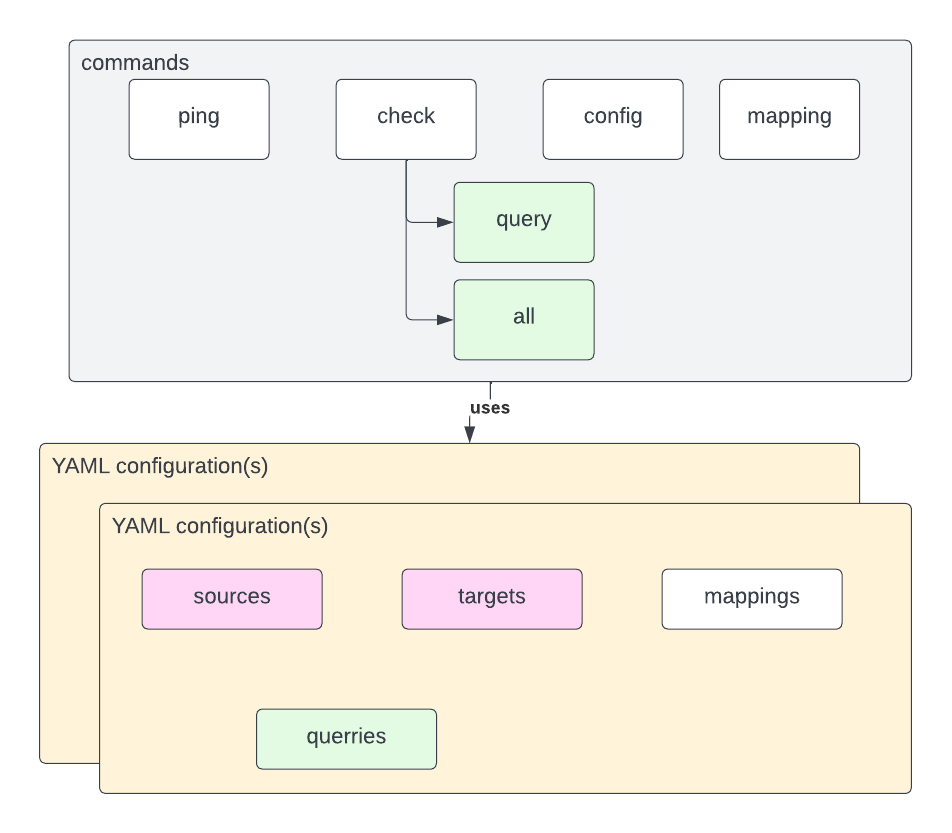
ping- will test the connection of source DB and target DBs defined in YAML configuration file usedcheck --query- will execute a single query identified by name from YAML configuration file usedcheck --all- will execute all queries identified by name from YAML configuration file usedconfig- use a differed YAML configuration filemapping- use a custom mapping defined in YAML configuration file
The Results
select-star uses goroutines to process millions of rows in seconds: (ex: 5milions of rows processed in ~34seconds)
Processed = queries executed on source DB and on target DB, rows compared, and differences highlighted in a HTML timestamped report!