
Every correction you give Claude Code disappears the moment the session ends.
You say “don’t mock the database in integration tests — we got burned by that.” Claude adjusts. Writes the real-DB tests. Nails it. Tomorrow you start a new session and the first thing it suggests is… mocking the database.
This isn’t a bug. It’s the architecture. LLM sessions are stateless. Context windows are per-conversation. The model doesn’t carry forward what it learned about your codebase, your patterns, your hard-won corrections.
So I built a system that does.
The Existing Landscape
This problem isn’t new and there are real tools attacking it. GraphRAG (Microsoft) builds a knowledge graph from documents — entities as nodes, relationships as edges — good for multi-hop reasoning across a corpus. Mem0 is probably the closest thing to what I built: a memory layer for AI apps with per-user stores, recency weighting, and conflict resolution. OpenMemory MCP is Mem0’s MCP-native variant that exposes the same idea as a server Claude can call directly. MemGPT / Letta gives the LLM a paging mechanism — main context plus archival storage it can query mid-conversation. Zep is the enterprise end of the spectrum: a memory graph product for LLM applications.
All of these are infrastructure for app builders. You wire them into your pipeline, your agent, your product. Brain is different: it’s a developer’s personal KB that the assistant queries autonomously — no app, no pipeline, just a Stop hook and an MCP server. And the core bet it makes is different too.
The Problem Is Signal, Not Storage
The naive approach is to dump every transcript into a vector store and RAG over it. That doesn’t work for three reasons.
First, most of a session is noise — scaffolding, exploratory questions, dead-end debugging. If you index everything, retrieval drowns in irrelevant results.
Second, the valuable moments are sparse and specific. A user correction (“no, use exponential backoff, not uniform sleep”) is one message in a 200-message session. A task completion, an error pattern, a solution that finally worked — these are signal moments scattered across hours of conversation.
Third, the recall needs to happen proactively. You can’t expect the user to remember to search. When Claude is about to write retry logic, the system should surface the backoff lesson before the mistake repeats.
Architecture: Hook → Extract → Recall
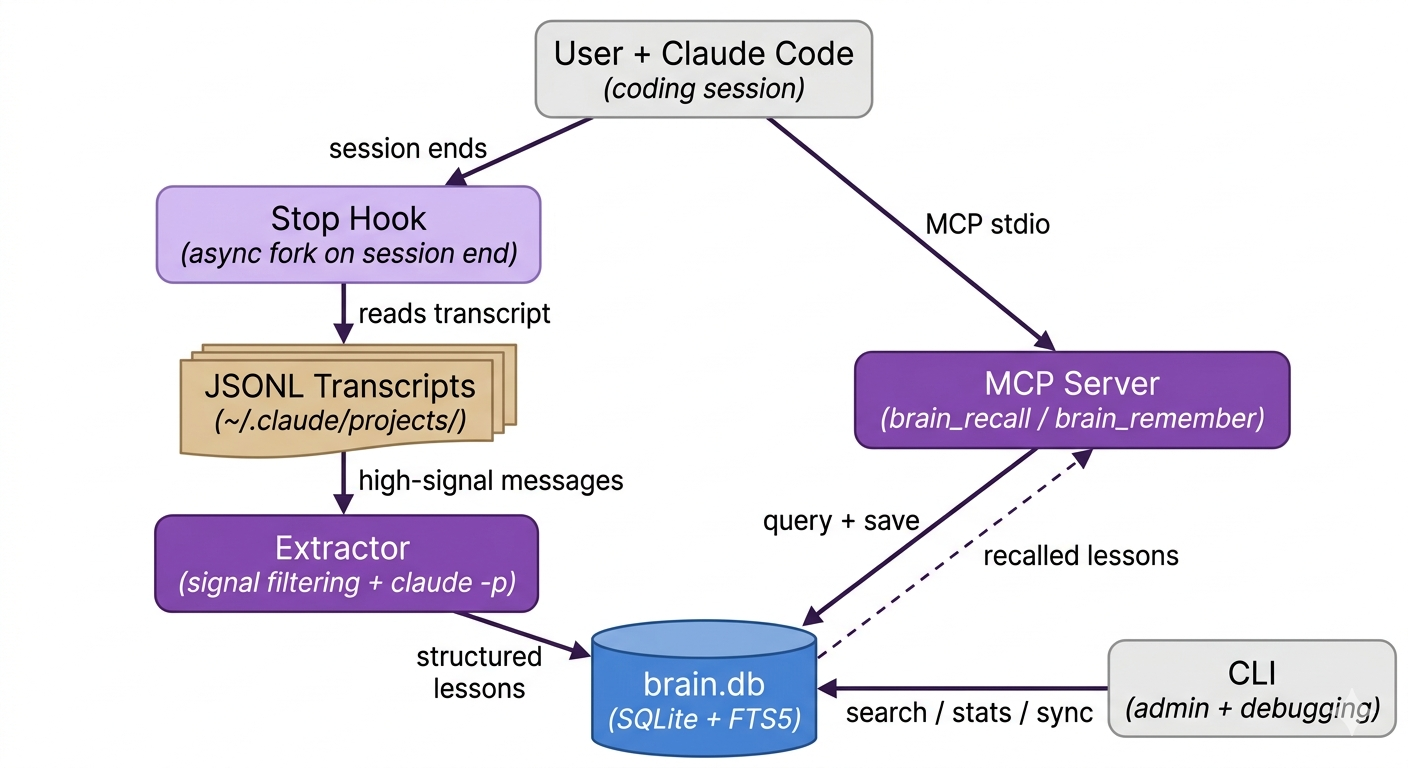
Brain is a single-file Python CLI (~2,000 lines) that wires into Claude Code at two points: a Stop hook for extraction and an MCP server for recall.
Capture
When a Claude Code session ends, the Stop hook fires. It reads the session transcript (JSONL), filters for high-signal messages — errors, user corrections, task completions, explicit #cor markers — and sends them to claude -p (Haiku by default) with a strict extraction prompt.
The extractor scores signal moments by context: error clusters, correction language, solution patterns. It returns a JSON array of structured entries, each with a type (lesson, antipattern, decision, pattern, snippet), a signal level (HIGH, MED, LOW), and optional flags (AVOID, HARD-WON, 10X).
Store
Entries go into SQLite with FTS5 full-text indexing. Content-hash IDs make re-syncs idempotent — you can reprocess a transcript without duplicating entries. Soft-deletes (unlearned flag) let you remove bad entries without losing data.
The key design choice: fail-closed sync. If the Claude CLI call errors during extraction, the transcript is not marked as synced. It retries on the next run. Long-running sessions get re-extracted when they grow by ~20KB, so a session you left open all day doesn’t lose its last three hours of work.
Recall
Brain exposes three MCP tools that Claude calls automatically mid-conversation:
brain_recall— search the KB before writing code, making decisions, or debugging. Uses FTS5 with quoted-token safety and LIKE fallback.brain_remember— save a new lesson during a session, without waiting for extraction.brain_extract— trigger on-demand extraction using the current model instead of background Haiku.
When Claude is about to suggest a pattern, it queries brain_recall with concrete nouns from the task. If the KB has a matching antipattern or correction, it surfaces before the code is written — not after.
What 30 Days of Daily Use Actually Taught Me
I started Brain on April 24th. Forty-six commits later, across 11 evaluation versions, the system works — but getting here was a process of using it every day, inspecting the output, and fixing what was actually broken rather than what I thought would break.
Extraction quality is the bottleneck, not retrieval
My first instinct was to tune retrieval — better FTS queries, smarter ranking, more context in recall results. That was backwards. The real bottleneck was extraction: only 4.8% of transcripts were being successfully extracted in v10’s production audit. Timeouts, schema mismatches, I/O errors. When extraction did run, the lessons were high-quality. The system wasn’t wrong — it was just barely running.
The fix wasn’t algorithmic. It was operational: better timeout handling, retry logic, regrowth detection for long sessions. Old-school reliability engineering applied to an AI pipeline. (yeah, old school programming and debugging in this period of time ..)
Stale lessons are safer than I expected
My biggest fear was that Brain would recall an outdated lesson and lead Claude down the wrong path. I tested this deliberately in v10 — seeded a stale lesson about a function that had been renamed, then watched what happened.
Claude recalled the stale entry, recognized it didn’t match the current code, and explicitly noted the discrepancy. No harm done — just a few extra tokens. The model’s own verification instinct acted as a safety net. Safe to ship, even without a staleness expiration mechanism.
The #cor marker changed how I interact with Claude
Once I added the #cor tag (from correct - yeah is hard to name things) — a way to guarantee a correction gets captured — my feedback became more intentional. Instead of casually saying “no, not like that,” I started writing #cor that's the wrong approach, use exponential backoff not uniform sleep. The correction got extracted every time. The specificity improved because I knew it would be remembered.
A capture mechanism changes the input behavior. When you know corrections persist, you invest more in making them precise.
Single-file design was a deliberate trade-off
Brain is one Python file. No framework, no separate modules, no package structure. The mcp library is the only external dependency.
This makes it trivial to install (ln -s into $PATH), easy to audit (one file to read), and simple to debug (one log, one DB, one entry point). The trade-off is that the file is ~2,000 lines and covers CLI, MCP server, extraction, storage, and logging. For a solo tool that I use daily and iterate on rapidly, that trade-off pays off. For a team project, it wouldn’t.
The A/B evaluation harness proved its weight
I built a small eval framework early: 5 real-world test cases (FTS5 quoting, SQL upsert patterns, fork error handling, sys.exit() in libraries, enum validation), each with a hand-written seed lesson and an extractor-produced alternative. The eval scored both on precision, conciseness, and actionability.
Eleven versions later, every hypothesis I had about “this prompt change will improve extraction” was checked against real cases before shipping. Most hypotheses were wrong. The eval caught them. The discipline of measuring before deploying — old-school QA applied to prompt engineering — prevented several regressions that would have corrupted the KB.
Using It
pip install mcp
chmod +x brain.py
sudo ln -sf "$(pwd)/brain.py" /usr/local/bin/brain
brain install # writes Stop hook + MCP registration
brain sync # extract lessons from existing transcripts
brain doctor # verify everything is wired up
After install, Claude Code calls brain_recall automatically via MCP. No manual steps. The CLI commands are for admin and debugging:
brain stats --health # daily health check
brain search "cache" -n 10 # quick lookup
brain last 10 # see latest extractions
brain recall-log 20 # what Claude is recalling
brain compact --dry-run # preview duplicate cleanup
The --html flag on stats generates a self-contained dashboard with entry counts, signal distribution, and a recalls-per-day chart. Dark mode included.
What’s Not Solved Yet
Brain is not finished. It’s driving enhancements, not declaring victory.
Extraction coverage is still the biggest gap. Many transcripts fail extraction due to size limits, timeouts, or edge-case formatting. The retry mechanism handles transient failures, but systematic coverage requires better chunking strategies for very long sessions.
Cross-project learning works but lacks nuance. A lesson learned in one repo gets recalled in another, which is sometimes exactly right and sometimes irrelevant. Project-scoped filtering exists but the heuristics for “when to go global” need refinement.
Confirmation tracking is new and unproven. Brain now logs when a recalled entry appears in a subsequent session, which should eventually feed into a confidence score. The data is accumulating. The scoring isn’t built yet.
Brain is not finished and I’m not claiming it’s better than the tools above. For me it works — and it still needs improvements. What I can say is that it’s a light, single-file tool that reduces the groundhog-day loop: you correct something, it disappears at session end, you correct it again next week. That’s the whole value claim. Hard-won lessons don’t reset. For a daily dev workflow, that’s enough to be useful.
Three things I’d take away from this:
The hardest part of persistent AI memory is extraction, not retrieval. Getting the right lessons out of a 200-message transcript is a harder problem than searching a clean database. Invest in the capture pipeline first.
Daily use reveals what benchmarks miss. Eleven eval versions, 46 commits in 30 days — and the most important improvements came from using the tool every morning and noticing what felt wrong. A/B evals validate hypotheses. Daily use generates them.
AI tools benefit from old-school engineering discipline. Fail-closed sync, content-hash dedup, idempotent re-syncs, structured logging, soft-deletes — none of this is novel. All of it is necessary. The AI part is a thin layer on top of reliability patterns that have worked for decades.
The correction you make today should stop the same bug from shipping next week. That’s the entire value proposition — and getting it right is as much about plumbing as it is about prompts.