
In my last post about writing AI agent specs, I made the case that the spec is the product — that code is just a side effect of a well-structured checklist. The idea came out of building 5level, an 8-agent SDLC framework covering everything from product manager to release lead.
That post was about how to write a good spec. This one is about what happens when you take that foundation and push it further — using real side projects to stress-test the ideas, tighten the workflow, and find out what actually breaks.
Knowing how to write a precise agent spec and doing it consistently across a full project are two different problems. Between a well-structured SKILL.md and a shipped feature, there’s still friction: remembering which workflow step you’re on, knowing which agent to invoke, keeping the backlog honest. So I took the 5level framework and distilled it into three skills — repeatable, invocable, and opinionated.
Three Skills, One Loop
The workflow is simple: design → build → ship. Each step is a skill. You invoke it, the agent does the loop, you review and approve, then move to the next.
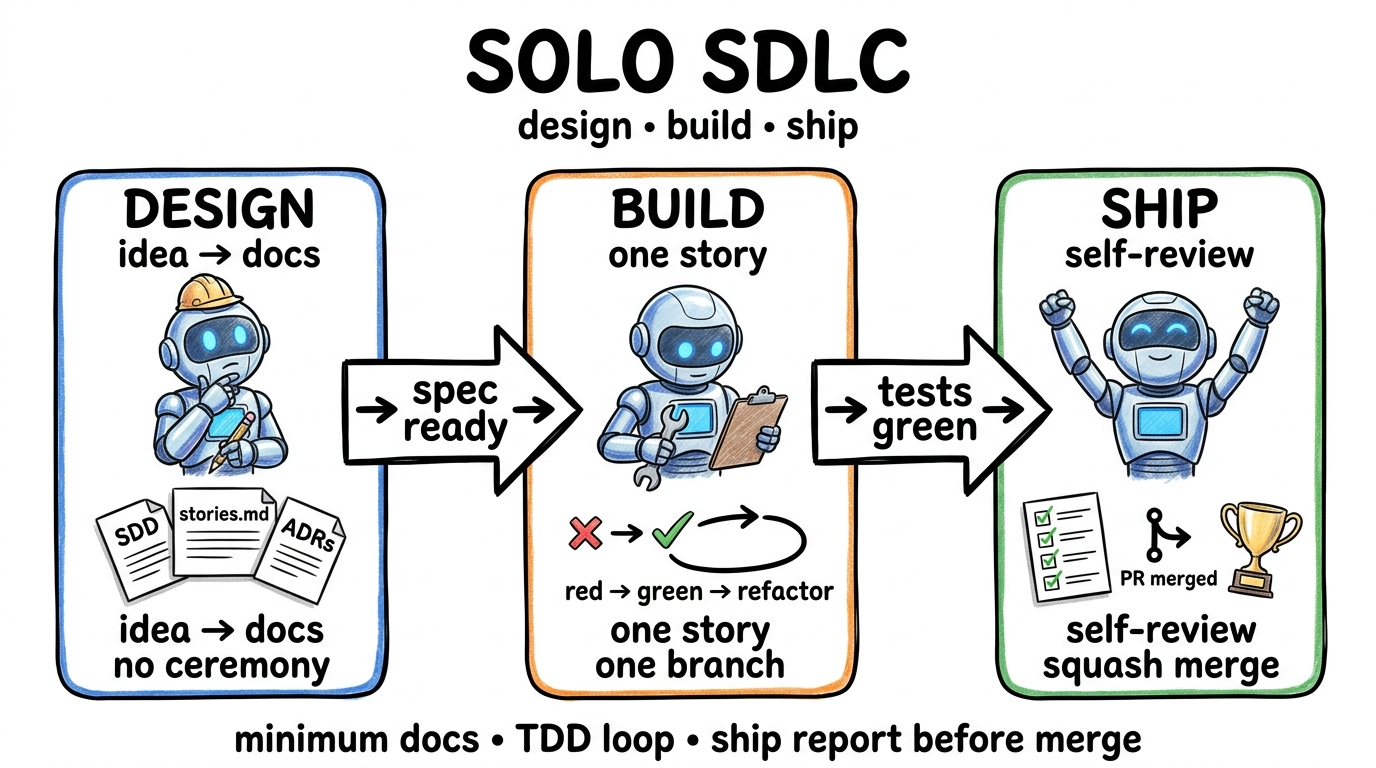
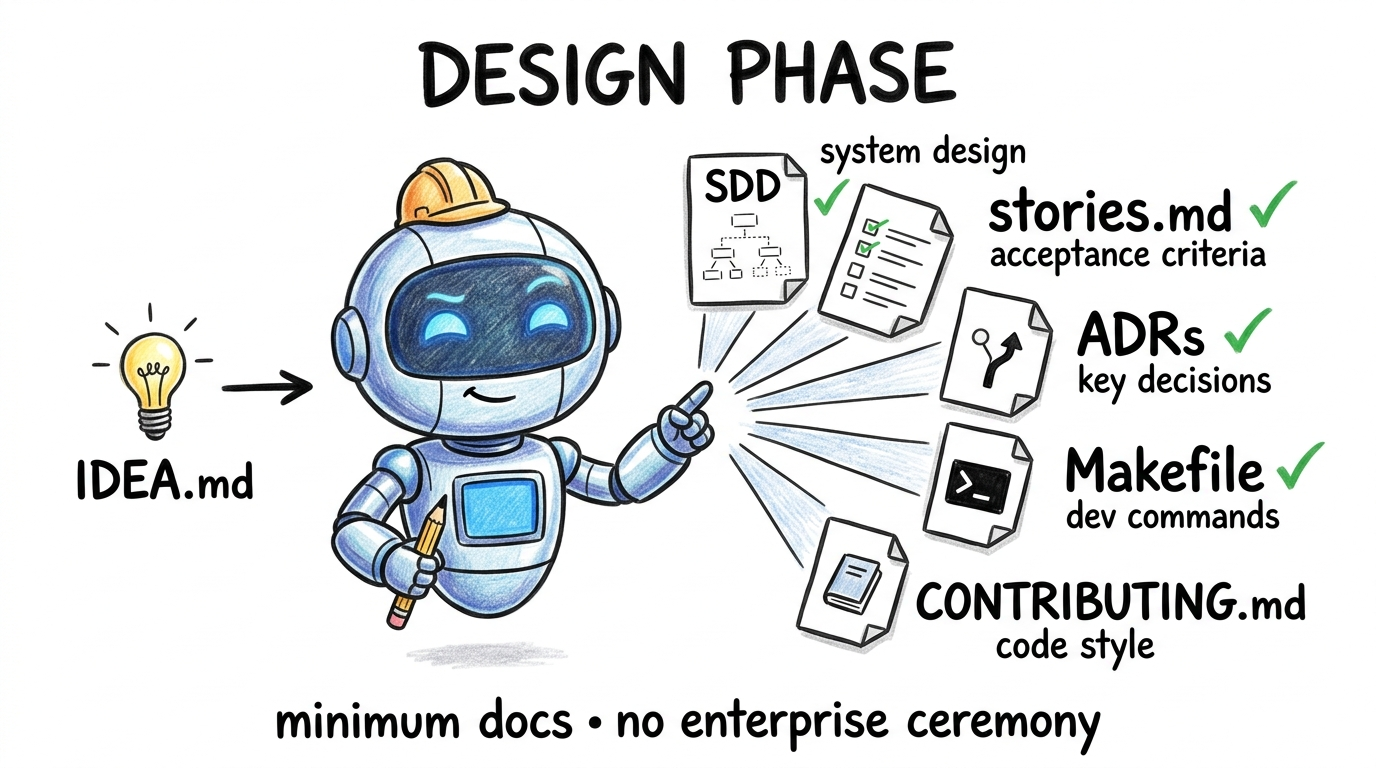
/sdlc-design
Takes an idea and produces implementation-ready documentation — an SDD, a stories.md backlog with user stories and acceptance criteria, and ADRs for any real architectural trade-offs. No enterprise ceremony. Designed for solo developers who need just enough structure to build from, not a document that will outlive the project.
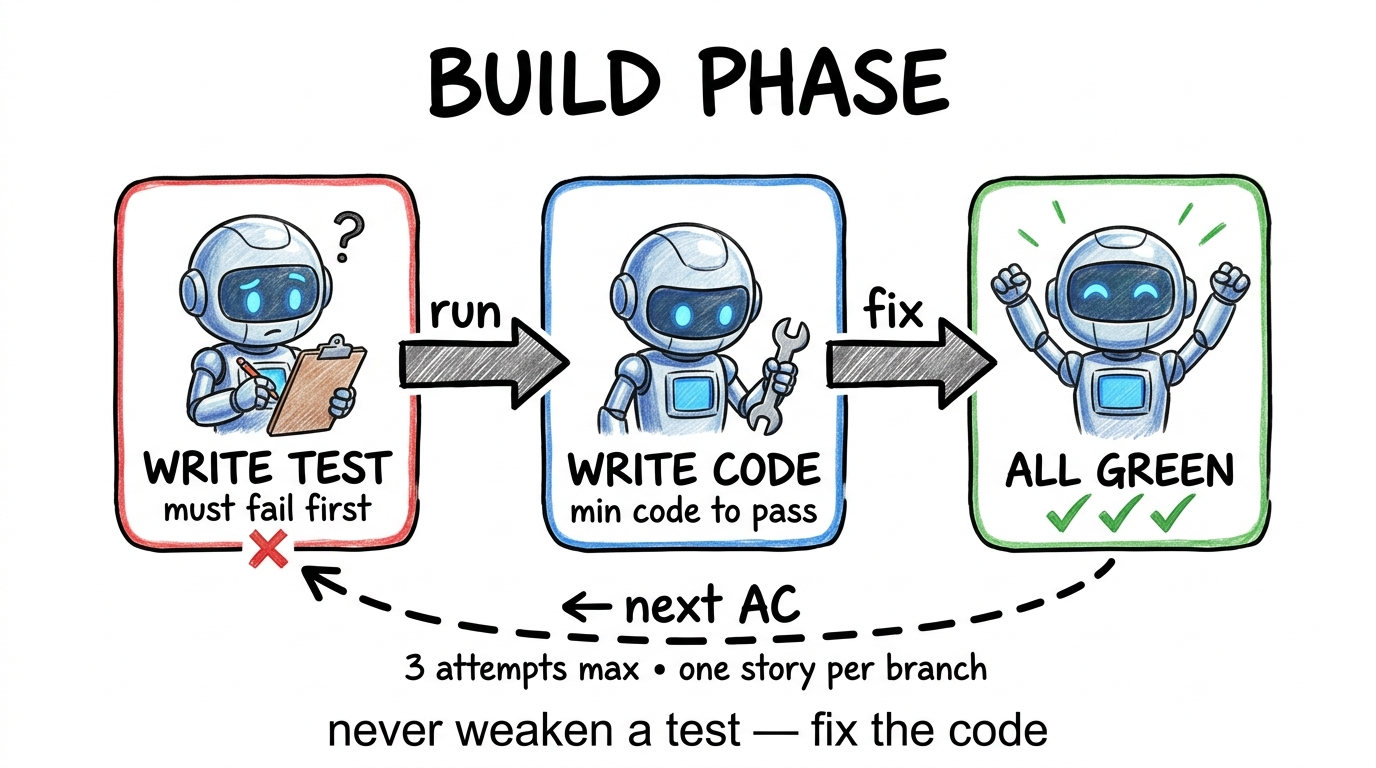
/sdlc-build
Picks a story from the backlog, creates a feature branch, writes a failing test for each acceptance criterion, implements the minimum code to pass, and commits. Red → green → refactor, one AC at a time. The story is never “done” until every checkbox on the Definition of Done is satisfied — the agent verifies this before stopping.
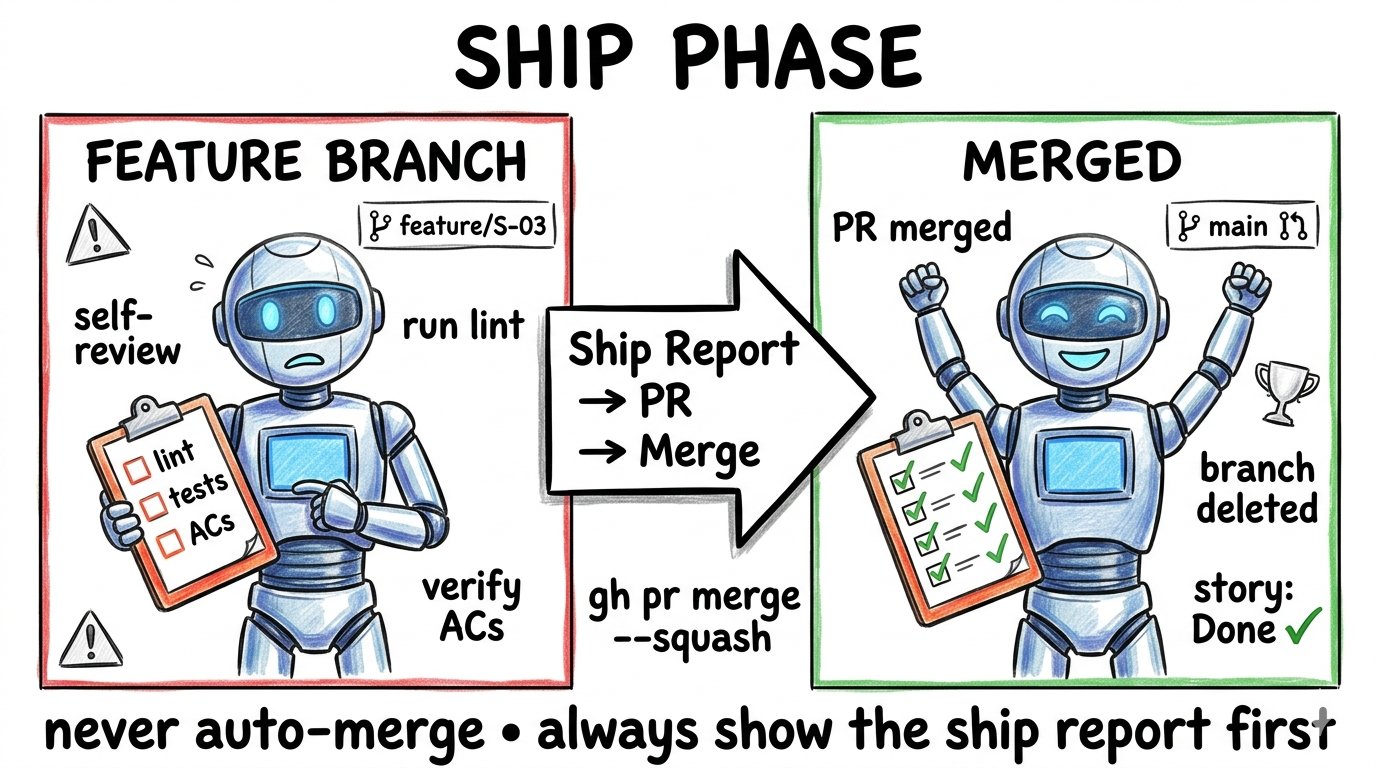
/sdlc-ship
Self-reviews the branch for logic bugs, edge cases, and security issues that linters miss. Creates a PR with a ship report. Merges to main. Marks the story complete in stories.md. You get a verified merge and an up-to-date backlog without touching git manually.
What Actually Happened
I used these three skills on two projects back to back.
The first was StoryTime — a bedtime story generator I built with my daughter, where she helps write the story and local models generate the cover images. First commit on March 18th. By March 22nd — four days later — 40 stories were designed, implemented, and shipped. To be honest about what that means: these were small, well-scoped stories. Typical AC count was 3-5 items. Nothing architecturally complex. What the number reflects isn’t raw feature size — it’s how much overhead normally gets in the way of shipping small things, and how much of that overhead disappeared.
The second was Jarvis — my personal AI assistant, built as a tiny 3D robot that lives in the corner of your screen: always on top, hotkey-activated, context-aware. Not a demo, not a side experiment — a tool I actually use every day. Init commit on March 19th. First release tag three days later.
What moved fast wasn’t code generation — that’s table stakes at this point. What moved fast was the loop: functionality decision → spec → implement → review → ship → repeat. Each cycle was hours, not days. The bottleneck was never the agent.
You’re Not the Builder Anymore
This is the thing that takes a while to actually internalize.
In both side projects, my job was almost entirely functional review: does this story capture what I actually want? Does this PR do what the story says? Is this edge case worth a follow-up story or can I live without it? The questions were product questions, not implementation questions.
The mental shift is less like adopting a new tool and more like moving from individual contributor to tech lead. Your leverage goes up. But so does your responsibility for the clarity of your own thinking — because when the spec is vague, the agent doesn’t block on you. It fills in the gap. And the gap compounds across ten stories before you notice.
Here’s a concrete example. During Jarvis, I wrote a story for the hotkey activation behavior. I said it should “toggle the robot’s visibility.” I meant: if it’s hidden, show it; if it’s showing, hide it. The agent interpreted “visibility” to include opacity transitions — so it built a fade in/out system with configurable duration. Perfectly reasonable reading of the word. The PR looked fine. I approved it. Three stories later, I hit a conflict with another story that assumed instant show/hide for a tray-click behavior. I had to go back, reopen the story, and re-ship. Twenty minutes lost because I said “visibility” when I meant “display state.”
That’s not a failure mode of the tooling. That’s a failure mode of imprecise language — which the tooling amplifies, because it executes confidently on whatever you gave it.
Specification quality is the new bottleneck. Not implementation speed. Not test coverage. Not deployment. The one thing that consistently slows everything down is the moment you hand an agent an ambiguous requirement and don’t catch it until the PR.
If you haven’t read the post on agent spec patterns — that’s the foundation this sits on.
The Part That’s Harder Than It Looks
You will ship more, faster. That part is real.
But the framing that “the human is the new bottleneck” is only half true — and it’s the comfortable half.
The human bottleneck is real, but overstated
Yes, the loop runs fast. Faster than humans are comfortable operating at. The loop — design, review, merge, new story, review, edge case, ship, next feature — creates cognitive overhead that adds up in a way that doesn’t feel like overwork but does feel like something is off.
It’s not exhaustion from effort. It’s exhaustion from switching. Every handoff from agent to human is a context reload — what was I looking at, what decision am I making, what’s the criteria here. Do that thirty times in a day and you’ll finish having shipped a lot, feeling more drained than a day of deep coding would leave you.
The practical adjustment: timebox review sessions. Don’t let the agent queue set your pace. Batch the decisions, do a focused review window, then close the loop. Treat it like a standup, not a stream. If you catch yourself approving a PR because it looks reasonable rather than because you verified it does what the story says — stop. That’s the mental state where spec ambiguity debt accumulates.
The agent has its own failure modes
The agent is also a bottleneck — just not in the way you expect.
It optimizes for green tests, not coherent software. Each story gets implemented against its own acceptance criteria. That’s the design. But software isn’t a collection of independent stories — it’s an integrated system, and the agent doesn’t hold that in mind across branches. When story S-12 implements a setting and story S-23 adds a UI for it, the agent may pick completely different patterns for each. The tests pass. The feature works. The code quietly diverges.
It doesn’t push back. A human teammate will sometimes say “wait, doesn’t this conflict with what we did last week?” The agent won’t, unless you’ve built that check explicitly into the skill. It will implement what you ask, confidently, even if it contradicts an earlier decision. Refactoring stories fix this — but only if you write them, and only if you notice the drift first.
Context limits are a silent constraint. In a long session, the agent’s awareness of earlier architectural decisions fades. Early in a project, it might choose a clean abstraction. Thirty stories later, working within a grown codebase, it may duplicate logic it can no longer fully see. The tests still pass. The duplication compounds.
Self-review is not independent review. /sdlc-ship includes a self-review step, and it catches real issues — missing edge cases, logic bugs, obvious security gaps. But an agent reviewing its own output has inherent blind spots. It’s unlikely to question whether the whole approach was right, or flag that three different files now do similar things in different ways. Structural problems pass through.
What actually suffers: the product as a whole
The individual features work. The stories get done. But there’s a class of quality that story-by-story delivery doesn’t protect — and that’s coherence.
After 40 stories, the inhouse tool functioned. Every feature did what its story said. But using it end-to-end revealed rough edges that no single PR review would catch: flows that technically worked but felt disjointed, error messages that were inconsistent across screens, one part of the app that used keyboard shortcuts and another that didn’t because those stories were written three days apart and neither referenced the other.
None of this was wrong. It just wasn’t thought about. And the loop doesn’t naturally create the space to think about it, because the loop is always pointing forward to the next story.
The fix isn’t to slow down — it’s to schedule deliberate “whole product” reviews separate from the story loop. Step out of the queue, use the actual application as a user would, and write polish stories for what you notice. Treat UX coherence as its own backlog item, not as a property that emerges from shipping features.
Three things I’d take away from this:
The loop is the leverage, not the code generation. The value isn’t that an agent writes code faster — it’s that the full cycle runs in hours. That changes what’s possible for a solo developer.
You’re not the builder anymore, and that’s a harder shift than it sounds. Your job becomes clarity. When the spec is vague, the agent fills the gap confidently. The gap compounds. Specification quality is the real bottleneck — not implementation speed, not test coverage, not deployment.
Velocity without coherence is incomplete. The agent optimizes story by story. Tests go green. Individual features work. But coherence doesn’t emerge automatically — consistent patterns, flows that feel right end to end. Someone has to own that view. It has to be you.
The tools give you speed. They shift the burden of quality onto your thinking, not your typing. The faster the loop runs, the more expensive a vague requirement becomes.