
The AI ecosystem nudges you toward big models and heavy frameworks. Neither is required when the task is clear. The smallest useful agent is a loop, a local model, and a file.
I built project_local_agents on that premise: production-ready local LLM agents from scratch — no LangChain, no CrewAI, just Python loops and typed dispatch. What I want to share isn’t what each agent does. It’s the architecture that makes the whole thing work without collapsing under its own complexity.
Small Models Do Real Work
The key insight is that most agent failures are scope failures, not model failures. The failure mode I see most isn’t “model too weak.” It’s “task too broad.” Nail the scope and a 3B model does the job.
MLX makes this practical on Apple Silicon. Local inference at 3B/7B scale — no API, no cost, no data leaving the machine. The models aren’t impressive in the general sense, but “impressive” is the wrong criterion. “Does it reliably extract structured output for this one task?” is the right question, and the answer is often yes.
What “small enough” looks like in practice: JSON schema output, one tool at a time, a clear stop condition. If you can write down what done looks like before you start, a small model can probably get you there.
An Agent Is a Loop
Here’s the entire pattern, before any framework reaches for it:
while True:
decision = call_llm(context, tools) # typed union: ToolA | ToolB | Done
if isinstance(decision, Done):
break
result = dispatch(decision)
context.append(result)
Five lines of logic. Everything a framework gives you — retry handling, tool routing, context management, observability — is built on top of this loop. The question is whether you need all of it before you’ve proven the loop works.
YAGNI applies here harder than almost anywhere else. The loop is the proof of concept. Add orchestration only when the loop provably can’t do it.
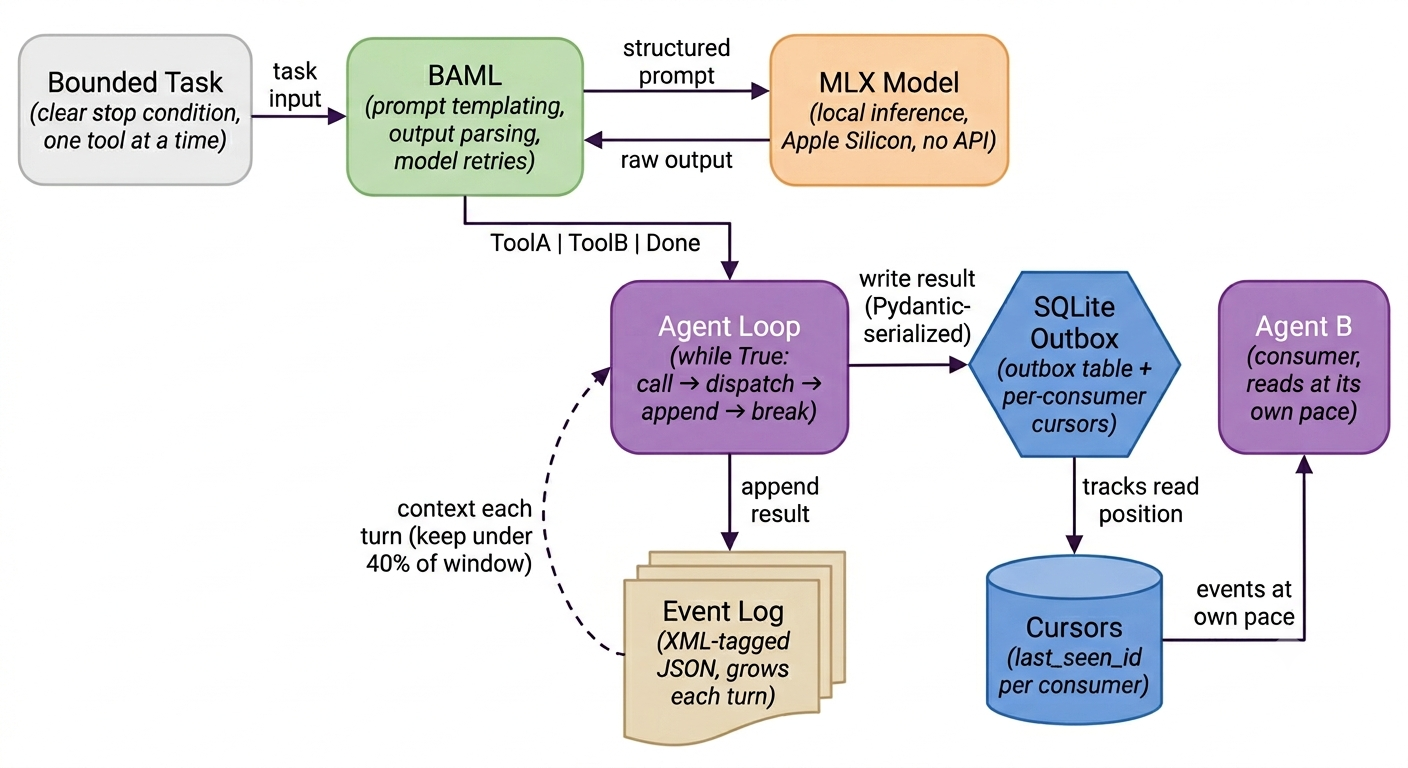
BAML handles typed dispatch: the LLM returns ToolA | ToolB | Done — no string parsing, no intent matching, no fragile regex. This matters because it separates two different contracts. BAML handles the LLM boundary: prompt templating, output parsing, model retries. Pydantic handles Python-to-Python boundaries: bus serialization, validation, schema. Don’t conflate the two — they serve different purposes and conflating them is how you end up with untestable spaghetti.
Context as Events, Not State
The agent doesn’t maintain external state. Instead, it builds a growing event log — XML-tagged JSON — that gets fed back to the model each turn.
<event type="fetch_result" ts="2024-01-15T10:30:00">
{"repo": "owner/project", "files": [...]}
</event>
<event type="analysis" ts="2024-01-15T10:30:05">
{"finding": "missing test coverage in auth module"}
</event>
This is debuggable, portable, and requires no external system. You can replay any session by feeding a recorded log back into the loop — which gives you reproducible tests for the dispatch and tool logic without stubbing anything.
One operational constraint worth designing around: keep the event log under 40% of the model’s context window. Past that threshold, the model starts dropping earlier events even when they’re still in-context. This is empirical — tested across 3B and 7B models on MLX. At 40%, recall degrades noticeably. The practical implication is that this bounds agent turn depth, which forces you to scope tasks tightly. The architecture reinforces the discipline from the section above: bounded tasks, not open-ended ones.
The Event Bus for Composition
When you have more than one agent, they need to share results. The temptation is a message broker — Kafka, RabbitMQ, something that feels like proper infrastructure.
The minimal version is a SQLite outbox table with per-consumer cursor rows.
CREATE TABLE outbox (
id INTEGER PRIMARY KEY,
agent TEXT NOT NULL,
event_type TEXT NOT NULL,
payload JSON NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE cursors (
consumer TEXT PRIMARY KEY,
last_seen_id INTEGER DEFAULT 0
);
Producers write results. Consumers read at their own pace. Independent deploy. Zero infrastructure. Agents don’t need to know about each other — they write to the bus and read from it. That’s the entire coupling contract.
This works until you need strict ordering guarantees, exactly-once delivery, or distributed consumers across machines. Cross those bridges when you actually reach them.
Why This Architecture Is Testable
This is the angle the “just use LangChain” crowd doesn’t cover.
The SQLite event bus is inherently inspectable. SELECT * FROM outbox WHERE agent = 'fetch_agent' is your assertion. No mocking the coordination layer — the bus is a file. Spin up a test SQLite in a temp directory, write events, assert consumer behavior. No fakes, no patches, no drift between test and production.
The event log is replayable. Capture a real production run, feed it back into the agent loop in CI, and you get a reproducible test for the tool and dispatch logic rooted in real behavior — the kind that actually catches regressions.
Typed dispatch means tool calls are assertion-friendly. isinstance(decision, FetchRepo) beats parsing "FETCH_REPO" out of a string every time. The type system does the work; the test just checks the result.
These testability properties fall out of the architecture for free. They weren’t bolted on afterward. The choices that made the system simple — SQLite over Kafka, typed unions over string parsing, event log over external state — are the same choices that made it testable. That’s not a coincidence.
Four things I’d take away from this:
Small models do real work when the task is clear. The failure mode is almost never “model too weak” — it’s “task too broad.” Fix the scope and the model size stops mattering as much as you think.
An agent is a loop. Start there. Frameworks add value eventually, but they cost you simplicity immediately. Don’t pay that cost until you’ve proven the loop isn’t enough.
Coordination doesn’t need infrastructure. A SQLite file with a cursor is enough to let independent agents share results without coupling them. Kafka-scale problems require Kafka. Most agents don’t have Kafka-scale problems.
If you can’t test it, you don’t own it. Inspectable state, replayable logs, typed assertions — all of this comes free from the architecture above. The testability wasn’t added later. It was already there.
The pattern isn’t complex — the complexity arrives when you reach for solutions before you’ve proven you need them.